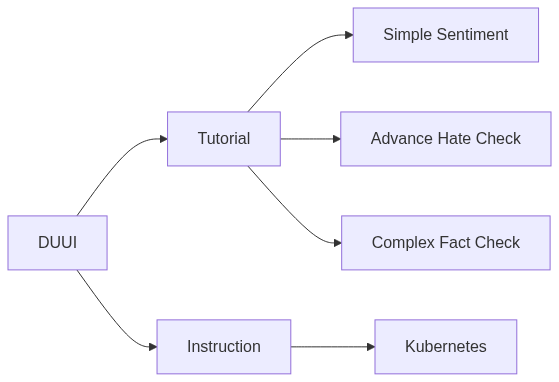
Tutorial
This documentation is designed as a tutorial for the creation and integration of new NLP analysis tools to be used within the Docker Unified UIMA Interface (short DUUI). For this purpose, the tutorial is structured in two parts: a general part describing DUUI and the global context as well as several concrete examples for creating your own components based on existing DUUI components.
Note
We recommend reading the following publication before using the tutorial:
DUUI in a nutshell
What is DUUI?
Docker Unified UIMA Interface (DUUI) is a UIMA-based framework for the unified and distributed use of natural language processing (NLP) methods utilizing micro-services such as Docker or Kubernetes. Through DUUI, flexible pipelines for the analysis of unstructured information, currently texts, can be processed based on documents. The processing can be distributed both, horizontally (on several nodes) as well as vertically (several times on the nodes), using a cluster solution for Docker or within Kubernetes.
DUUI is implemented in Java and can be used in this way, whereby a web-based solution for encapsulation is currently also being recommended; DUUI essentially consists of three elements:
-
Composer
It controls the start of the Components (which perform the actual analysis(es)) - and terminates them as well - and is also responsible among other things for performing the analysis.
-
Driver
DUUI contains a set of Drivers which provides an interface for the execution of Components in a respective runtime environment (Docker, Docker Swarm, Kubernetes, Java Runtime Environment, etc.).
-
Component
A Component encapsulates a defined NLP analysis within a Docker image, which is used for analysis as a Docker container independently and autonomously as an instance for analyzing documents as part of a pipeline. This guide is intended to explain the creation of a Component.
Further information as well as the DUUI project, which can be reused under the 
![]() as well as in the
as well as in the .
Important
For using DUUI as a Java application, a JRE of at least 17 is required.
For whom is DUUI?
DUUI is designed as a general framework for the uniform analysis of unstructured information (text, video, audio and images) and is intended to be used in a variety of disciplines. Above all, the straightforward extension of new analysis methods, the completeness of the resulting data as a UIMA document, the reusability in databases and as well as the flexibility of the annotation format in combination with a web-based interface should streamline, standardize and improve the utilization of NLP processes.
However, since the usability of DUUI goes hand in hand with the amount of available components and since different analysis methods exist for various applications and research, the development of individual analysis methods as DUUI-Components represents a core task for users.
In medias res
With the basics now explained in a nutshell, the tutorial can begin, whereby we also refer to existing DUUI-Components that are already available and which can all be used as for new components.
The creation of DUUI components
In order to create a DUUI component, three building blocks are required, which are explained in detail in the following instructions
| TypeSystem | Lua-Script | Programm |
|---|---|---|
| The TypeSystem (as part of UIMA) defines the schema of the types of annotations which are created by the component. This TypeSystem is necessary for DUUI to understand the annotated document. | The Lua script enables any component to (de)serialize annotations from a UIMA document in a programming language-independent approach without the need for native UIMA support in the respective programming language. | The analysis is a script / program which operates as a REST interface and uses or reuses an existing analysis or an existing program to perform the actual NLP analysis. |
Tip
Generally, the complete TypeSystem from Texttechnologylab can be integrated in a DUUI tool. But this normally contains far more Types or Typesytems than might be needed for a specific tool. However, the idea of DUUI is that each component only returns the TypeSystem that can be created by the component.
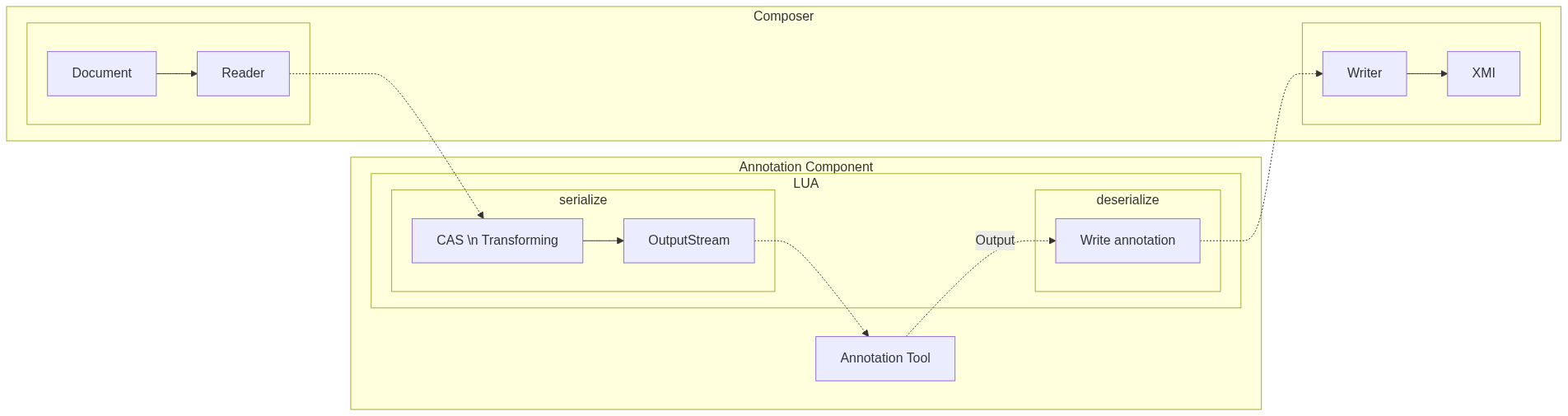
Pipeline
The DUUI Pipeline for a component starts with reading the document and ends with writing the annotations back to the document.
The graph below shows the flow of the pipeline. After reading the document, they are passed to a Lua script which extracts the needed information and passes it to the analysis tool. The analysis tool then returns the annotations which will be deserialized by the Lua script and written back to the document.
For a complete pipeline you can check the tutorials.
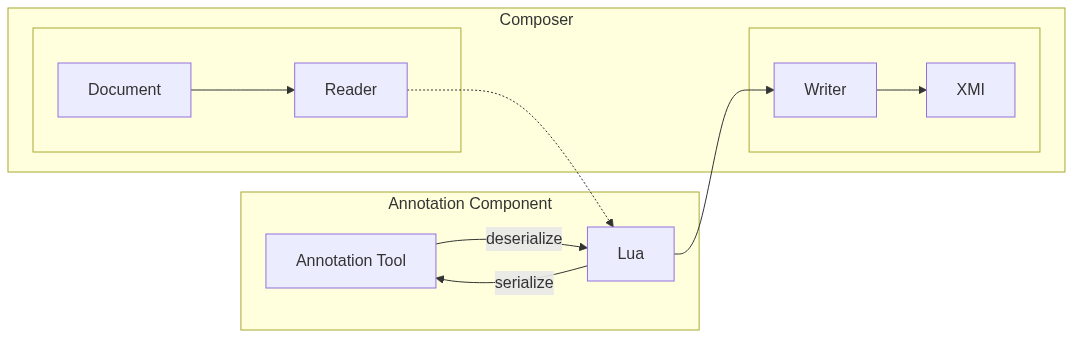
Lua script
The Lua script is used as a communication interface between the annotation tool and the DUUI composer.
The script contains two parts, the first being the serialize function that is called to transform the CAS object into a stream that is sent to the annotation tool.
The second part is the deserialize function that is utilized to transform the output of the annotation tool back into the CAS object.
For different examples of Lua scripts you can check our tutorials.
Docker
Docker is used to run the tool. Docker containers are used to ensure that the analysis is performed in the same environment, regardless of the underlying host system. Also, the Docker container is used to ensure that the analysis is reproducible, because every build of the Docker container is versioned, containing all needed code and data (e.g. model files). The diagram below shows the structure of a Dockerfile:

Rest Interface
The DUUI is designed to be used with REST interface, which is defined as:

The REST interface is used as a standardized way to communicate with the DUUI.
- GET /v1/typesystem is the TypeSystem that is used by the analysis tool, which contains all UIMA types.
- GET /v1/documentation is the documentation of the analysis tool, which should contain at least the annotator name and the version as fields. Optional parameters can be added.
- GET /v1/communication_layer is the communication layer that is used by the analysis tool. This represents the Lua script, with the serialize and deserialize functions. In this way, DUUI enables the tool to supply its own communication layer that can be easily and dynamically executed in the DUUI context without having DUUI to “know” all tools beforehand.
- POST /v1/process is the processing function that is used by the analysis tool. This function is called for every CAS document in the pipeline. Therefore, it is the main function of the analysis tool.
Tutorials
We have prepared three tutorials with different levels of complexity. All tutorials use Python as the programming platform, however, all languages where a REST service can be created could be used as base for a DUUI tool.